Deploying instances
Deployment in productive environments often groups a set of physical or virtual machines. In Magnolia, different deployment possibilities are introduced in the next section. You can read more about the clustering options further down this page and on Setting up Jackrabbit Clustering.
Data deployment models
This section compares different ways to store data between Magnolia instances. Each option has its pros and cons.
Option 1: Completely separate instances
Each instance has a dedicated database and runs on different physical hardware.
| This setup is good for zero downtime. |
Tolerant, highly available, completely redundant
Duplication of data and cost of resources to keep them

Option 2: Centralized database server
A centralized database server holds the copies of JCR repositories for each instance. The instances run in separate virtual machines.
| This setup is performant but not disaster tolerant. |
Reduction of database instances
Includes separated data redundancy
The database is a single endpoint, and a clustered installation is recommended to avoid failure
Increments in infrastructure and total vCPU units

Option 3: Clustered data model
All public instances run in a cluster.
Data flow is centralized in a clustered environment
Faster publishing
Decreases processing on the author instance, as it only needs to send one copy of the data
Your data relies on only one copy, and so you need backup policies
If the cluster goes down, you lose all visibility

Clustering setup
Magnolia can be configured to run in a clustered environment to provide high availability and load balancing:
-
High-availability clusters are also known as fail-over clusters. Their purpose is to ensure that content is served at all times. They operate by having redundant instances which are used to provide service when a public instance fails. The most common size for a high-availability cluster is two public instances, the standard Magnolia setup. In such a setup the redundant instance may even be dormant (not actively serving content) until it is called to service.
-
Load-balancing clusters connect many instances together to share the workload. From a technical standpoint there are multiple instances but from the website visitor’s perspective they function as a single virtual instance. A load balancer distributes requests from visitors to instances in the cluster. The result is a balanced computational workload among different instances, improving the performance of the site as a whole.
Conditions for clustering
If you consider to use clustering - make sure the following conditions are true for your project and the environment you are running it:
-
You are in full control of the virtual machines (VMs) on which the cluster is running.
-
Your public instances are not treated as
disposablewith automatic up/down scaling based on load OR Your public instances use the database (cluster) running on separate VM that is not disposable. -
The amount of writing (JCR) data is not too high.
Reason: Each write action generates a record in the journal table that is used to synchronize all cluster nodes - thus generating additional chatter and load on each node (also due to sync of index).
-
You do not update Magnolia too frequently or do not require high availability. (When updating clusters, all cluster nodes except one need to be shutdown, and restarted with new libs after the first node was updated successfully.)
When above conditions are not met, it is in all likelihood better to avoid using cluster and distribute data by other means instead. (For instance use REST services to write data directly from client or using Magnolia Public instances as proxy writing to such externalized service and being accessible from/via all instances).
Jackrabbit clustering
We use Jackrabbit’s clustering feature to share content between Magnolia instances. Clustering in Jackrabbit works on the principle that content is shared between all cluster nodes. This means that all Jackrabbit cluster nodes need access to the same persistent storage (persistence manager and data store). The persistence manager must be clusterable.
Any database is clusterable by its very nature as it stores content by unique hash IDs. However, each cluster node needs its own (private) file system and search index.
| For more details, see the Apache Jackrabbit clustering documentation and these instructions for setting up Jackrabbit clustering. |
Individual workspaces can be mapped to different repositories. The repository that holds shared content can reside in clustered storage. This is useful for content that needs to be in sync across all instances.
In the diagram, each Magnolia instance uses its own persistent storage for storing the content of website, dam and config workspaces. However, the comments workspace has shared content that is stored in a clustered storage, the database in the middle.
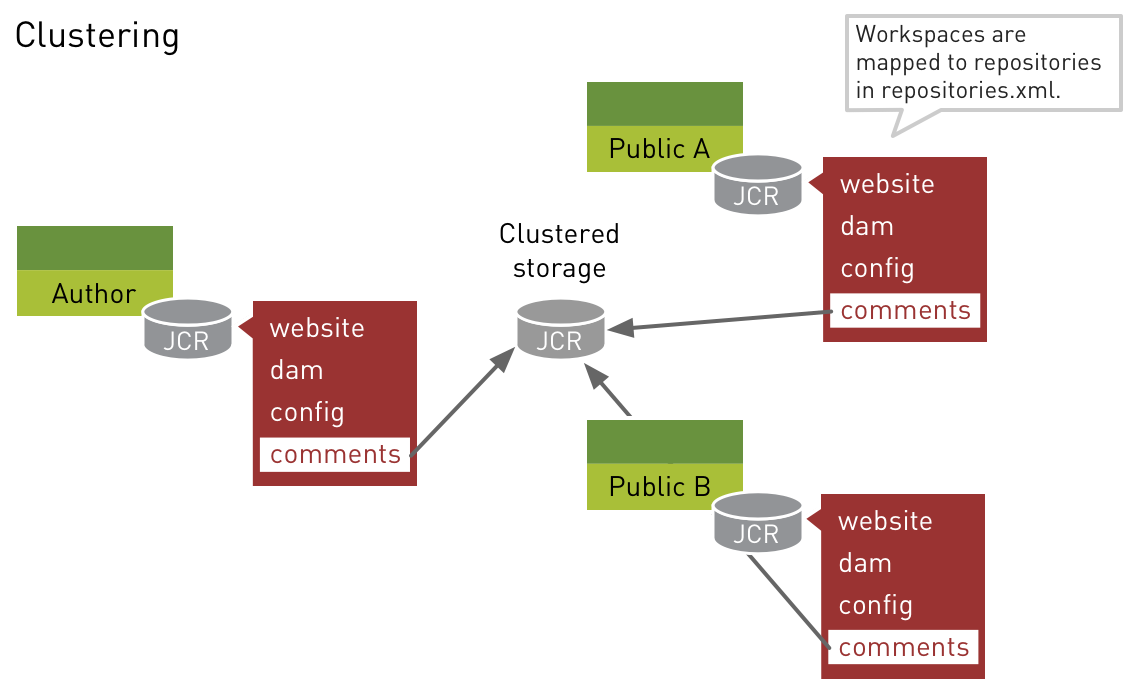
User generated content such as comments written by site visitors is a typical clustering case. Imagine that users John and Jane request the same web page. A load balancer redirects John to public instance A. When John leaves a comment on the page, his comment is stored in a workspace that resides in clustered storage. Now Jane requests the same page. The load balancer redirects her to public instance B. John’s comment is immediately visible to Jane since both instances tap into the same clustered storage.
Other examples of shared content are user accounts, permissions of public users and forum posts. They need to be available regardless of the instance that serves the page.
Cleaning the Jackrabbit journal
Cluster nodes write their changes to a journal that can become very large over time. By default, old revisions are not removed automatically so that you could easily add new cluster nodes. Since Jackrabbit 1.5, a process called Janitor automatically cleans the database-based journal. For more on its configuration, see Configuring the Jackrabbit Janitor Thread.
To enable Janitor, see Removing Old Revisions and Add new instances to your Jackrabbit cluster.
|
Note the following about using Janitor:
|