Jackrabbit search
By default Magnolia’s search functionality is provided by the Jackrabbit repository and this page describes the configuration options for Jackrabbit-based search. For more advanced search options and especially if you need to manage high volumes of assets you can set up Magnolia to use Apache Solr, see Solr search.
How search indexing works
Indexing is the process of collecting and parsing content, and storing the data in an index to make information retrieval fast and accurate.
Magnolia search is based on the default Jackrabbit search implementation. Jackrabbit uses an Apache Lucene-based indexer to process the data stored in the JCR. An index makes it faster to retrieve requested portions of the data. Node names and property values are indexed immediately and stored in the repository. Text from documents is extracted in a background process which makes document content searchable after a short delay.
You can find the physical index folders and files on the file system in
/<CATALINA_HOME>/webapps/<contextPath>/repositories/magnolia/workspaces/*/index.
See the Jackrabbit Search wiki
to learn how to configure search indexing from scratch and more about
the options available with the implementation. The workspace.xml file
mentioned on the wiki is in
/repositories/magnolia/workspaces/<name of workspace>.
Typically, each Magnolia instance has its own repository and its own index. This means that the author instance index is typically different from public instance indexes. Any content that has not been published to a public instance cannot be found when running a search on that public instance.
Magnolia index configuration
Magnolia uses a custom Jackrabbit/Lucene indexing configuration. The
indexing configuration file is in the Magnolia Core module in
/src/main/resources/info/magnolia/jackrabbit and
org.apache.jackrabbit.core.query.lucene.SearchIndex gets it from the
classpath.
The generic indexing configuration used for all
workspaces except the
website workspace is stored in
/info/magnolia/jackrabbit/indexing_configuration_default.xml. The
indexing configuration for the website workspace is in
/info/magnolia/jackrabbit/indexing_configuration_website.xml. You can
configure indexing for additional workspaces by setting the workspace
name in
<param name="indexingConfiguration" value="/info/magnolia/jackrabbit/indexing_configuration_${wsp.name}.xml"/>
in the workspace.xml configuration file.
If you are updating your Magnolia to 5.6.2 or
later, we recommend you to set the indexing configuration by specifying
workspace name(s) in the indexingConfiguration parameter.
|
These configurations fine-tune the default Jackrabbit search configuration for best results. The sections that follow detail the enhancements.
|
Special characters Jackrabbit stores all character data (node names and values) in Unicode. This ensures that special characters such as accents and umlauts are indexed and can be used in search. Issues with special characters are often due to character set conversion problems in the application server. See URI encoding in Tomcat for more. |
Excluding nodes
Magnolia typically stores many properties, such as author, modification
dates, templates etc., that are not relevant in search results. To
minimize the index and speed-up search, all properties starting with
jcr: or mgnl: are excluded from the index. This means you get fewer
results but those results are more relevant.
<index-rule nodeType="nt:base">
<property isRegexp="true" nodeScopeIndex="false">mgnl:.*</property>
<property isRegexp="true" nodeScopeIndex="false">jcr:.*</property>
<property isRegexp="true">.*:.*</property>
</index-rule>Boosting the title property
By default, indexing configuration boosts the title property of the
mgnl:page node type since page titles are important.
<index-rule nodeType="mgnl:page">
<property boost="3.0">title</property>
</index-rule>Including areas and components
The configuration uses
index
aggregates to ensure area and component content is included in the
index. The properties of mgnl:area and mgnl:component make up most
of page content and need to be included explicitly. The aggregate also
simplifies searching for content within pages.
Nested areas are also included using the recursive flag.
<aggregate primaryType="mgnl:page">
<include primaryType="mgnl:area">*</include>
<include primaryType="mgnl:component">*</include>
</aggregate>
<!-- areas can be nested. See http://wiki.apache.org/jackrabbit/IndexingConfiguration for recursion -->
<aggregate primaryType="mgnl:area" recursive="true">
<include primaryType="mgnl:component">*</include>
<include primaryType="mgnl:area">*</include>
</aggregate>Providing excerpts and highlighting search results
The workspace.xml file in each workspace enables highlighting in
search results and the Jackrabbit HTML
excerpt provider
class. The workspace.xml files are in
/<CATALINA_HOME>/webapps/<contextPath>/repositories/magnolia/workspaces/<workspace name>.
Here’s the relevant extract from workspace.xml in the contacts
workspace.
<!-- needed to highlight the searched term -->
<param name="supportHighlighting" value="true"/>
<!-- custom provider for getting an HTML excerpt in a query result with rep:excerpt() -->
<param name="excerptProviderClass" value="info.magnolia.jackrabbit.lucene.SearchHTMLExcerpt"/>|
If you have configured your own app
that operates on its own workspace and provides content for the website,
you need to add these parameters to the |
|
If you have used fields which allow for the storing of HTML, then that HTML will be indexed along with content. There is potential for the excerpt to contain HTML tags which are not closed. |
Implementing search using templating functions
There are many ways to implement search on a site. This section explains
how to do it using
templating
functions and uses the Magnolia Travel Demo site as an example. If the
demo modules are not installed your can download the
magnolia-travel-demo-parent module and
install the demo and tours modules.
The MTE module provides search templating functions that allow front-end developers to render search results using only a template script. A component model or Java knowledge is not required. This is how search is implemented in the Magnolia Travel Demo site.
There are methods for searching pages and other content, such as content
stored in content apps. The methods are exposed in templates as
searchfn and you can find templating examples at
searchfn.
All you need to implement search on a site is a component to retrieve the results from the search index and display them on the page.
This is how search works on the Magnolia Travel Demo site.
-
searchResultscomponent searches pages and content apps for relevant results andsearchResults.ftlrenders this component. -
searchResultsPagetemplate autogenerates thesearchResultscomponent. -
Search results display on the
/travel/meta/search-resultspage that is based on thesearchResultsPagetemplate. -
/search-resultspage is assigned as the search page for the site in thehomePagePropertiesdialog
| See the travel-demo repository for specific examples. |
Displaying pages in the website workspace
The searchPages
method
displays pages stored in the website workspace in the search results.
This method retrieves pages whose content (text, image and other
properties) was added manually in the
Pages app, as opposed to content
retrieved from an app or another source. Set the root path of the site
to return the relevant items.
Here’s the snippet from searchResults.ftl in the Travel Demo. The root
path is /travel.
[#-------------- ASSIGNMENTS --------------]
[#assign queryStr = ctx.getParameter('queryStr')!?html]
[#-------------- RENDERING --------------]
[#if content.headline?has_content]
<h2>${content.headline}</h2>
[/#if]
[#if queryStr?has_content]
[#assign searchResults = searchfn.searchPages(queryStr, '/travel') /]
[#assign recordsFound = searchResults?size /]
<h3><em>${recordsFound}</em> ${i18n['search.pagesFoundFor']} "${queryStr}"</span></h3>
<div class="list-group">
[#if searchResults?has_content]
[#list searchResults as item]
<a href="${cmsfn.link(item)}" class="list-group-item">
<h4 class="list-group-item-heading">${item.title!}</h4>
<p class="list-group-item-text">${item.excerpt!}</p>
</a>
[/#list]
[/#if]
</div>
<#-- More processing here, not shown in snippet >
[/#if]
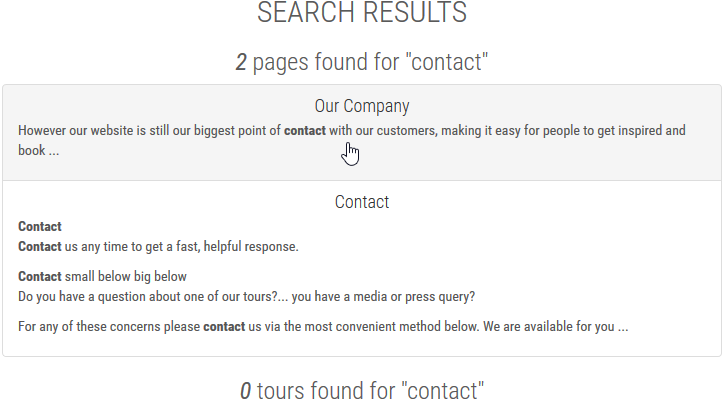
Here are the results for the term contact.
Excerpts and
highlighting are provided automatically by the
indexing configuration.
Displaying content stored in apps
The searchContent
method
allows you to search any content in the JCR. The method is useful to
display pages whose content is stored in another workspace. In this
scenario you need to set the
workspace where the
content is stored, the parent URL within that workspace and the
node type.
In the Magnolia Travel Demo site all Tour content (text, images and
more) is entered in the Tours app and retrieved by a component that
displays the content on pages. The app content is stored in the tours
workspace, under /magnolia-travels and is of node type mgnl:content.
Here’s the snippet from searchResults.ftl that retrieves Tours app
content.
[#assign searchResults = searchfn.searchContent('tours', queryStr, '/magnolia-travels', 'mgnl:content') /]
[#assign recordsFound = searchResults?size /]
<h3><em>${recordsFound}</em> ${i18n['search.toursFoundFor']} "${queryStr}"</span></h3>
<div class="list-group">
[#if searchResults?has_content]
[#list searchResults as item]
<a href="${cmsfn.link(item)}" class="list-group-item">
<h4 class="list-group-item-heading">${item.description!}</h4>
<img src="${damfn.getAssetLink(item.image)}" class="img-responsive img-rounded" height="80" width="160" alt="${item.description!}"/>
<p class="list-group-item-text">${item.excerpt!}</p>
</a>
[/#list]
[/#if]
</div>
Here are the results for the term swiss.
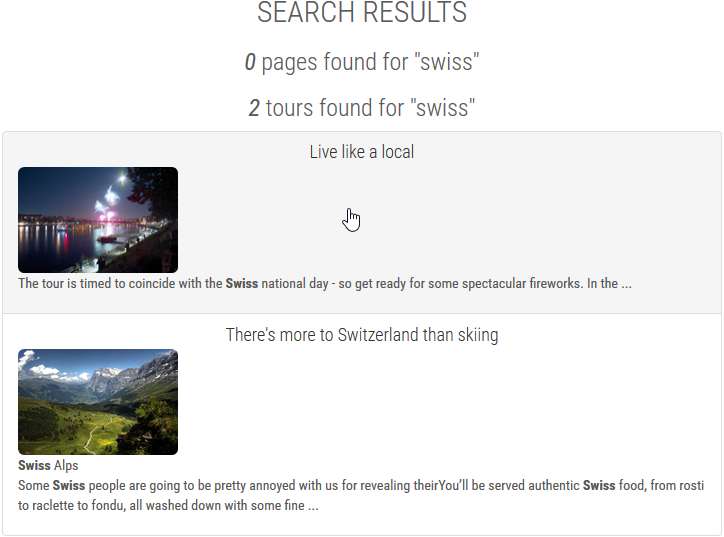
URI mappings
Best practice
When you display results from content app workspaces, build a link to a detail page that displays the content item in question using URI mappings.
URI mapping is used in the Demo Travels example to display app content on pages and ensure that the content is included in the search index. URI mapping is a way to redirect incoming requests to the location of the content.
Configuring URI2Repository mapping
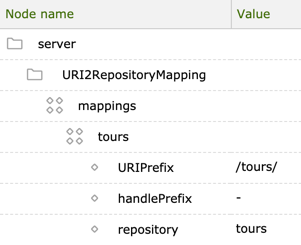
The URI2Repository mapping URI mapping mechanism determines which repository node should be served when a particular URI is requested.
Here’s the URI2Repository mapping for the tours workspace in
/server/URI2RepositoryMapping/mappings/tours.
| Property | Description |
|---|---|
|
|
|
Injects the |
|
Repository the mapping applies to. |
Configuring VirtualURI mapping
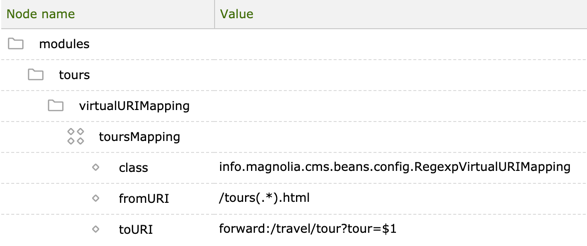
Virtual URI mapping allows you to create short, convenient URLs.
Here’s the virtual URI mapping for the Tours app in
/modules/tours/virtualURIMapping/toursMapping.
| Property | Description | ||
|---|---|---|---|
|
Tours virtual URI mapping node.
|
||
|
|
||
|
Path to tours in the tours workspace as mapped in the |
||
|
URI to which tours are forwarded |
Customizing search
You can customize search by writing your own queries to search the index and execute them in code. A query returns a result set which you can display on a page.
You can test your queries in the Query subapp. When you get the result set you want, implement the query in code.
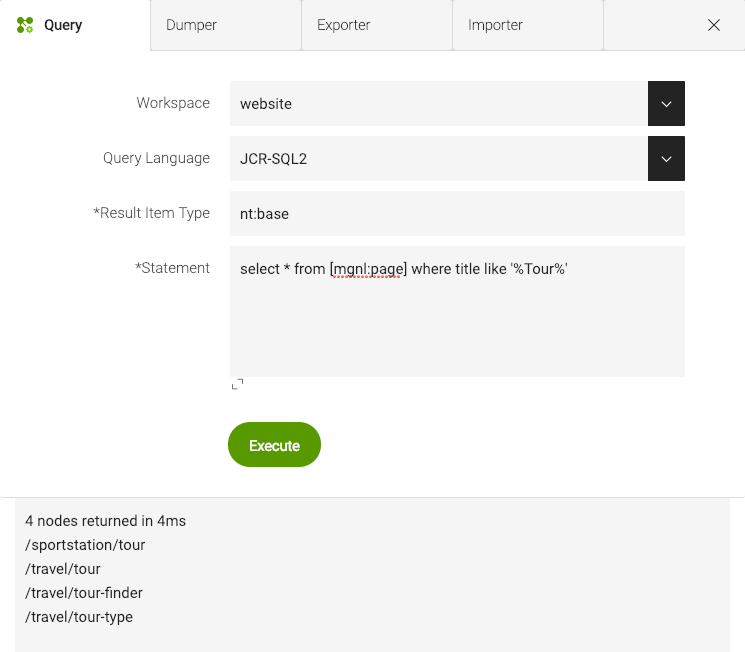
Example queries
The following queries are written in SQL-2. See JCR Query Cheat Sheet for more examples.
-
Find pages that contain the word
swiss.
Workspace: website
SELECT * FROM [mgnl:page] AS t WHERE
ISDESCENDANTNODE([/tours]) AND
CONTAINS(t.*, 'swiss')-
Find modules that have commands. This query looks for a folder named
commandsin the module configuration.
Workspace: config
SELECT * FROM [mgnl:content] AS t WHERE
ISDESCENDANTNODE([/modules]) AND
name(t) = 'commands'-
Find assets that are not JPG images under the
/examplepath in the DAM.
Workspace: dam
SELECT * FROM [nt:base] AS t WHERE
([jcr:primaryType] = 'mgnl:asset' AND
[type] <> 'jpg') AND
ISDESCENDANTNODE([/example])
ORDER BY [t].title ascSecurity
Search within Magnolia is access controlled. Search results include only content the user has permission to access. Permissions are controlled through Security. When you execute a query in info.magnolia.context.MgnlContext, contextual factors such as the current user’s permissions are taken into account. If you do not have permission to the items you are querying, they will not show up in the results.